Perl's parser is very flexible: its behaviour can be changed at runtime and
this makes it difficult to statically parse.
Several tools attempt to statically parse or recognise a useful
subset of real-world Perl code such as
PPI (handwritten recursive descent parser in Pure Perl),
Compiler::Parser (handwritten recursive descent parser in C++),
Guacamole (parser based on BNF grammar built on the wonderful Marpa::R2),
and
PPR (grammar using regex recursive subpatterns).
This post will talk about some improvements to
Babble which extends PPR with a plugin
framework for source code transformation.
I will also cover a little bit about other approaches along the way.
What makes PPR1 interesting is that it is
implemented as a regex2 that matches subpatterns of Perl syntax
rather than an actual parser (i.e., PPR does not create a data structure at this time).
This means instead of having to write code that traverses a tree, you can write
out the subpatterns that you are looking for and insert code actions to handle what
you want to do as the regex engine encounters various pieces of the
syntax3. The PPR distribution offers two regexen:
$PPR::GRAMMAR: a standard Perl grammar with all rules defined in the formPerlRuleNameand$PPR::X::GRAMMAR: roughly the same grammar as$PPR::GRAMMAR, but each rule is defined as bothPerlRuleNameandPerlStdRuleNamewhich allows for overriding and extending the rules.
Babble uses the $PPR::X::GRAMMAR regex to
find and extract the positions
of submatches. To give an example:
use strict;
use warnings;
use feature qw(say);
use Babble::Match;
# Define what we want to match against.
my $match = Babble::Match->new(
top_rule => 'Document',
text => q{
for my $i (0..7) {
say $i;
}
for my $j (@list) {
say $j;
}
},
);
my @vars;
# Look up the definition of the PerlControlBlock rule in PPR::X:
$match->each_match_within( ControlBlock => [
# Match either for or foreach blocks
q{
for(?:each)?+ \b
(?>(?&PerlOWS))
},
# With a simple `my` declaration (full grammar supports
# `my`/`our`/`state` here and some other syntax)
q{
(?> (?: my ) (?>(?&PerlOWS)) )?+
},
# Capture a scalar variable name into the `variable` submatch
[ variable => '(?&PerlVariableScalar)' ],
# Match the rest of the `for` block
q{
(?>(?&PerlOWS))
(?> (?&PerlParenthesesList) | (?&PerlQuotelikeQW) )
(?>(?&PerlOWS))
(?>(?&PerlBlock))
},
] => sub {
my ($m) = @_;
push @vars, $m->submatches->{variable}->text;
});
say "variables found: @vars";
__END__
variables found: $i $j
This snippet matches any ControlBlock that also matches against the
submatch specification that is passed in as an ArrayRef. This specification
captures the iterator variable which is the only part we are interested in, but to know
where that variable is as part of the entire for-loop syntax, we need to use
other rules that are part of the PPR::X grammar.
Motivation
What brought me to using Babble was that I had written a set of modules which
use some features from newer versions of Perl and use modules that implement
new keywords using the pluggable keyword API from Perl v5.12. I use perlver
--blame from Perl::MinimumVersion to keep track
of what features I am using so I had some idea of what I needed to be
able to backport. So I ran Babble on my code and wrote a plugin to handle the
new keywords — my tests passed, the code ran on Perl v5.8.9 and it was now Pure
Perl by removing a dependency on an XS-only module. I was happy, but that's not
the end of the story.
Breaking ground
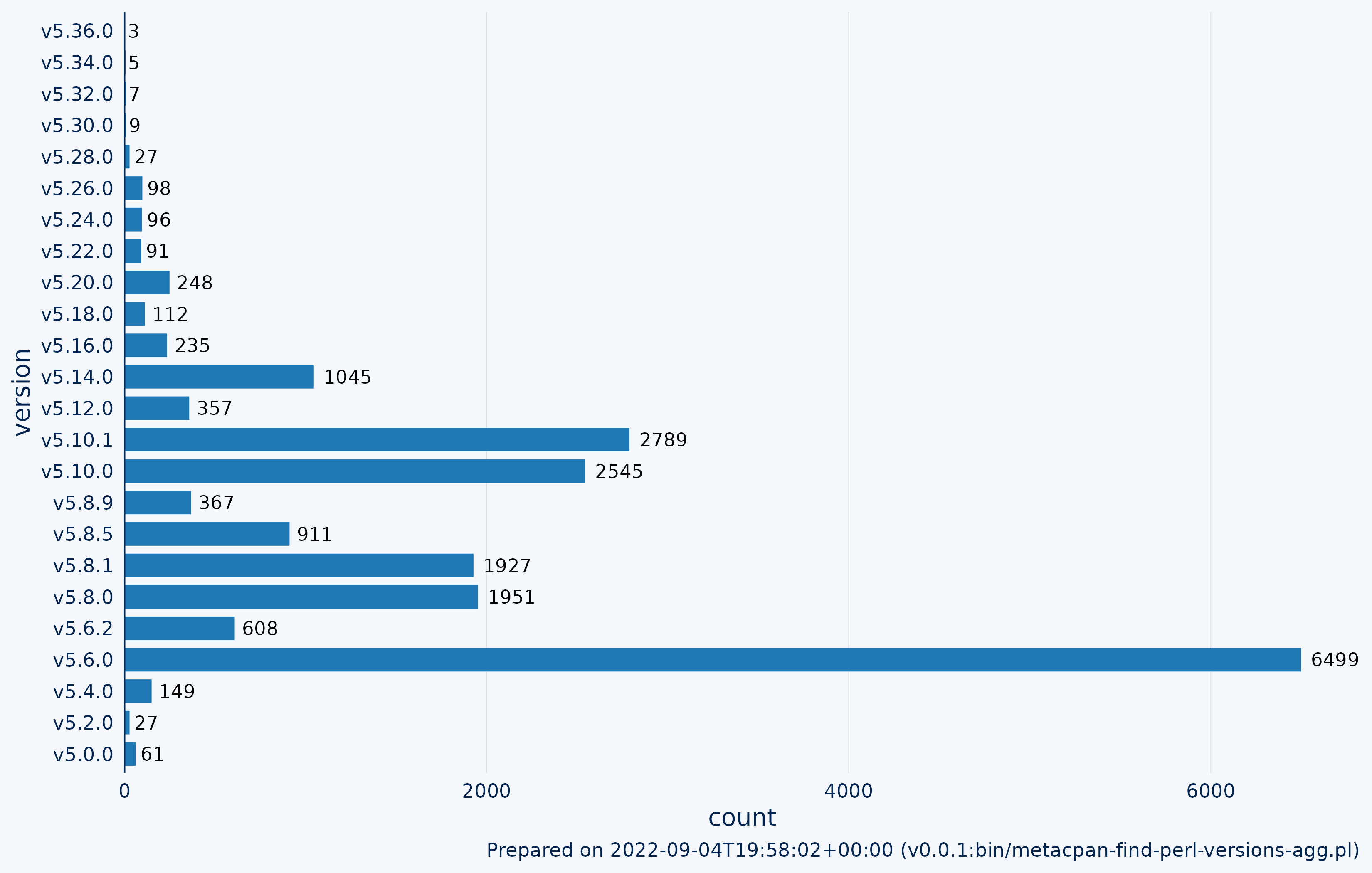
Typically when releasing libraries to CPAN, authors target the oldest version of the Perl interpreter they can support without having to backport features, syntax, and bug fixes while application code on CPAN has fewer constraints on the minimum Perl version. Since the majority of code on CPAN is library code, the following plot of minimum Perl interpreter versions shows that releases are skewed towards supporting older versions:
 |
Some of the features are easy enough to backport such as the
// (defined-or)
operator which can be turned into a ?: (ternary operator). Others are less
so, such as the /\b{wb}/ word boundary assertion
which is tied to properties in specific versions of the Unicode Standard.
Testing that source code transformation is correct by only running it on code
that I wrote is an “it works on my machine” approach. That's not very
satisfying. Let's find something a bit more challenging: grab some code off of
CPAN. Finding candidates for this is pretty easy with the MetaCPAN
API, but I already had something in mind: Dist::Zilla4.
Hold that thought, for now, I'll get back to it later.
I started by implementing the ellipsis statement (...).
The changes for this are fairly simple.
Just match any statement that entirely matches /\.\.\./ and replace it with a die.
Structural support
I then wanted to do something a little more daring: implement a keyword on top
of Babble. Well, not just a keyword, multiple keywords… that have their
semantics defined in another module. As before, this can not be statically
parsed, but keywords and custom syntax are still going to be used and people
want a solution. There are open issues about the API design to support this use
case on the PPI (The Keyword Question)
and the Guacamole (Pluggable grammars)
repositories.
The particular module that I needed this for is
Function::Parameters which
lets you create new keywords that occur in the same place in the grammar
as subroutine declaration (both named and anonymous)5. These keywords are
defined when imported and have per-keyword configuration options to
perform type validation, check argument count, and
automatically place the invocant
in a variable (e.g., method uses $self,
classmethod uses $class).
In order for the code generator to convert those definitions into Pure Perl
code, I need to access the configuration options used for the keywords.
A pattern that some Perl distributions use is to share imports among all the modules in a common setup module which exports those imports to whatever is using the common setup module. An easy way to do this is to use Import::Into. If we break the static parsing rule of “no evaluation of code” by loading just the setup module so that the parser can study what is imported, we can direct the parser and code generator.
Once we have the keywords that Function::Parameters introduces (in my case, I
have the keywords fun, method, and classmethod), we need to extend the
PPR grammar to match the parameter list just like Function::Parameters does.
We can extend the PPR::X grammar by adding more rules to match
what a single parameter looks like (optional type, sigil variable, optional
default value) and how these make up a comma-separated parameter list.
This is the approach I take here which
currently resides in my personal repository as I do not yet
want to release it for broader use.
I also wanted to be able to use the same rules I created for matching a
parameter list to help extract each part of the parameter, but to do this
I had to patch Babble so that ::Submatch objects use the same grammar as
::Match objects.
To test this, I created a small grammar to introduce class, extends, and
with keywords using Babble that are transformed into code that respectively
uses Moo classes, inheritance, and roles.
Keep digging
I then looked at the PRs that were already there: one by Mark Fowler presented a failing test case which I fixed. I also reviewed two PRs by Diab Jerius (1, 2).
I then read the code for some of the other plugins and noticed that the SubstituteAndReturn
plugin for non-destructive substitution
could not handle cases where the substitution is implicit or chained. When used inside of map,
the code is often both:
# chained implicit substitution
map { s/abc/1/gr =~ s/xyz/2/gr } @strings;
# is equivalent to making the implicit $_ variable explicit
map { $_ =~ s/abc/1/gr =~ s/xyz/2/gr } @strings;
# is equivalent to creating a copy and then applying in-place substitutions
map { (my $TEMP = $_) =~ s/abc/1/g; $TEMP =~ s/xyz/2/g; $TEMP } @strings;
The above transformation is essentially what this pull
request does. First, it looks
for statements that start with a substitution (meaning they have no binding
operator =~) and inserts a $_ =~ in front. Then it goes through and
replaces any chain of $lvalue =~ s/../../r =~ s/../../r ... with a map and for; for example
here is a test case:
[ '$foo =~ s/foo/bar/gr =~ s/(bar)+/baz/gr',
'(map { (my $__B_001 = $_) =~ s/foo/bar/g; for ($__B_001) { s/(bar)+/baz/g } $__B_001 } $foo)[0]', ],
I also found syntax that Perl::MinimumVersion does not yet detect: the
transliteration operator also takes an /r flag:
my @STRINGS = map { tr/a-z/A-Z/r } @strings;
# or y///r
I added support for transforming this syntax as well in the same pull request
and added support for detecting this to Perl::MinimumVersion.
Putting the blocks in place
Perl v5.12 introduced package version syntax and Perl v5.14 introduced package block syntax. These both slightly change the syntax of how packages are declared. The implementation for transforming to pre-v5.12 syntax is quite straightforward.
For package versions, just find package declarations (both statements & blocks) that have a version and turn the version into a string as in this test:
[ 'package Foo::Bar v1.2.3;
42',
q{package Foo::Bar;
our $VERSION = 'v1.2.3';
42}, ],
Converting the package blocks is also similar. Match any package declarations
that are package blocks and move the opening { of the block to right before
the package keyword and insert a semi-colon (;) after as in this test:
[ 'package Foo::Bar v1.2.3 { 42 }',
'{ package Foo::Bar v1.2.3; 42 }', ],
Do you notice that there is no dependency between the two plugins? You can apply them in either order.
μή μου τοὺς κύκλους τάραττε!6
Perl v5.20 introduced the postderef feature
which lets one write dereferencing write code that dereferences by using a
postfix syntax:
# ->@* is the postfix equivalent of the circumfix @{ }
# so
$diagram->{watch}{out}{archimedes}->@*
# is the same as
@{ $diagram->{watch}{out}{archimedes} }
Some of these can also be used inside of interpolated quote-likes (e.g., double
quotes) when the postderef_qq feature is enabled.
Turns out that PPR v0.000028
did not support all of the possible postfix dereferencing syntax. So I
submitted a bug to PPR
which Damian Conway fixed within a week. This version is non-backwards
compatible because it changed the definition of the PerlTerm rule which I
accommodated in Babble.
This also happened to fix the bug addressed by one of Diab Jerius' pull
requests! It also caused a regression in matching the state keyword
with attributes which was caught via the Babble test suite, but this was
fixed after
submitting a PPR bug report.
I then added support for converting postderef syntax within quote-likes.
While running this on the Dist::Zilla code I found code which uses the match
operator with single quotes:
my ($sigil, $varname) = ($variable =~ m'^([$@%*])(.+)$');
which does not interpolate the $@ inside. I also read the Perl documentation
closely and found that some special variables do not interpolate at all in
regexes:
# From `perlop`:
# > (Note that $(, $), and $| are not interpolated because they look like end-of-string tests.)
qr/ $( $) $| /x
I also submitted these as bugs to PPR.
I wanted to really stress-test the postderef_qq support by trying
different combinations. I started by reading the Perl interpreter source code
for interpolation in toke.c and found one undocumented case of
interpolation which is using ->$#* to access the array length
so I sent a patch to Perl itself to document it
(even though it isn't necessarily useful in the context of interpolation). I
also found that PPR was matching key-value slices (->%[ and ->%{) inside of
quote-likes when only value slices are allowed (->@[ and ->@{) so this was
also submitted as a bug report.
Once all those bugs related to matching postderef were fixed in PPR, my
tests related to syntax were passing and I opened another PR.
Careful with that sledgehammer
At this point, I felt confident enough to start automating the conversion of code. So I wrote a set of scripts that live here in the perl-leaning-toothpick-of-babble repository (alluding to 1, 2, 3).
Modifying code like this while debugging source code transformation is a repetitive process where you make a modification and then check it. To do this, I borrowed the second-order-diff technique from Tom Moertel which essentially lets you look at the diff between runs of your Big-Automated-SledgeHammer (BASH) so that you only have to review what has changed. It is a technique I have used for automating and verifying code refactoring before.
My BASH is a bash script called setup.sh.
I start by using
Git::CPAN::Patch
to pull down the latest tarball of a given release
and set this up as a git repository. I do this for
the releases of Dist::Zilla and its dependencies
which use syntax newer than Perl v5.8.9 which is checked
by trying to install and test each release using
an install of Perl v5.8.9; testing compatibility by
trying to run the test suite is more reliable
than using Perl::MinimumVersion.
I then
- remove comments and POD from the code so that there is less text to process;
- remove explicit Perl versions as in
use v5.36;in modules andMakefile.PLand removeMIN_PERL_VERSIONinMakefile.PL(though it would be better to only remove versions greater than the v5.8.9 target); and - remove
no feature 'switch'as several modules have that as boilerplate which will not work under Perl v5.8.9 as perModule::CoreList,feature was first released with perl v5.9.3.
After that preparation work, I can run Babble plugins on the code for each
release. It is important to note that I only run Babble automatically on code
in modules and not on testing scripts. This is because I want to make sure that
I leave the testing code as a control. This is possible because, as is best
practice with any testing code, the majority of testing code is written to be
as simple as possible and this means it is often already compatible with
Perl v5.8.9 syntax.
However, there are a couple of special cases which I run inside of setup.sh as
individual commands which are worth noting. First, there are two testing
scripts in Dist::Zilla which require being processed by ::DefinedOr and
::PostfixDeref plugins. I looked over these to make sure that the test behaviours
do not change. Second, there are two modules which use
Try::Tiny
which conflicts with the PPR::X grammar's support for the
try/catch syntax introduced in 5.34.0.
If the try/catch is not disabled in the grammar, PPR will consider the use of
Try::Tiny as invalid syntax and Babble can not process that code (not to
mention the semantics are very different). So I use a role to disable the
try/catch syntax as described in the PPR tests and individually process
those two modules. Note that this is essentially removing a keyword from the
grammar!
There are a couple more bugs that I reported and fixed as I repeatedly ran the
BASH followed by running check-perlver.sh and
run-tests.sh. They can be found in the Appendix.
Now after all that, I ran dzil new and dzil build under Perl v5.8.9 and I
got a releasable tarball. The whole process of applying the
BASH on all of Dist::Zilla and its dependencies takes
15 minutes on my computer. I have not yet tried to optimise it and in
particular the ::SubstituteAndReturn plugin uses a slow, but correct
algorithm.
The version of Babble with all these changes is on CPAN as Babble v0.090007_01.
Takeaways
There are a few paths for further work that I want to highlight.
Where this can be used
Processing code to use older syntax is not necessarily useful for all types of code. Furthermore, some features are not at the syntax level (e.g., Y2038 compliance) and other changes between versions of the interpreter fix bugs or security issues (e.g., hash randomization). So where can this be used? Mostly in toolchain code or code that works with toolchain code (e.g., for DevOps) as the Perl toolchain currently targets Perl v5.8.1 as a minimum. It is of course possible to write constrained code that supports that version by hand, but sometimes it is more natural to write code with more flexibility (and for more comfortable reading later). This is also the goal of libraries such as Mite which are targeted to be used in code that can be used along with the toolchain.
The ability to easily add (and in some cases remove) keywords to PPR
distinguishes it from the current implementations of other Perl static
parsing/recognition tools. This can make it possible to use it as part of more
general refactoring tools. While refactoring tools do exist, they are mostly
written on top of PPI. In some cases where I wanted to use refactoring with
those tools on code that uses a non-core keyword, I have patched PPI myself.
Regex copy and paste
Using PPR to extract smaller parts of syntax often requires copy-and-pasting
the contents of a set of regex alternative branches from inside the large PPR
regex. This could be fixed by adding more rule names for parts of the syntax
that are less meaningful on their own such as in ::PostfixDeref, I need
all the alternatives inside the PerlTerm rule that can take a postfix
dereference. However, I understand why one would not want to do this as
it would mean expanding the API with names that are less guaranteed to be
supported across versions.
Having the regex inlined into the plugin does have a benefit in that it lets you quickly see exactly what is being matched. Perhaps to fix this there needs to be a way to parse the regex itself for inclusion so that it does not have to be updated for small changes (because grammars generally do not change drastically).
Mixed parsing
Tools for static parsing of Perl do what they say on the tin: they will not run
the code. This is understandable for security reasons. Perhaps there can be a
tradeoff between static parsing and dynamic parsing by allowing the parser to
run only the use statements. Another additional approach is to record
information on the imports and parser state whenever the code is run, for
example, when the test suite is run.
The implementation I used above for Function::Parameters currently assumes
that the imports are at the top-level lexical scope of the file. Many keyword
modules are lexically scoped so they can be turned on and off throughout a
single file. To do this properly, we would need to walk the scopes (like in
Code::ART) and create a list of modules that are allowed to be imported for
the parser to study what they export. This can be done in a container for
security and cached for performance.
Operator precedence
In order to safely rewrite complex expressions that are not fully parenthesised, it will be necessary to implement operator precedence parsing. This is one of the difficult parts of parsing Perl statically as features such as prototypes can influence precedence and these can be defined far from the point of use in the expression.
Neither PPI7 nor PPR8 implements full
operator precedence
as part of their current implementation. On the other hand, Compiler::Parser and Guacamole both do implement operator precedence.
In Compiler::Parser, this is currently implemented by the
order of calls to a recursive descent
parser.
Guacamole currently implements operator precedence by using a hierarchy of
grammar rules.
MetaCPAN API
To find code that I could process using Babble, I used the MetaCPAN
API. It is very useful to be able to look up all the distributions that use a
particular module or grep over all the code on CPAN to find places where a
symbol or syntax is used.
Appendix: List of issues and pull requests participated in along the way
metacpan-examples
- Use Elasticsearch 2.x client and update some params by zmughal · Pull Request #23 · metacpan/metacpan-examples · GitHub
- Add debug flag for less verbose output by zmughal · Pull Request #24 · metacpan/metacpan-examples · GitHub
- Update reverse dependencies examples by zmughal · Pull Request #25 · metacpan/metacpan-examples · GitHub
Babble
- add broken test for a return that uses // by 2shortplanks · Pull Request #1 · shadow-dot-cat/Babble · GitHub
- optimize away empty signature; prevents syntax error on 5.10.1 by djerius · Pull Request #2 · shadow-dot-cat/Babble · GitHub
- don't treat array- or hash- lookups as postfix dereferencers by djerius · Pull Request #3 · shadow-dot-cat/Babble · GitHub
- Add support for the ellipsis statement by zmughal · Pull Request #4 · shadow-dot-cat/Babble · GitHub
- Use parent ::Match grammar in ::SubMatch by zmughal · Pull Request #5 · shadow-dot-cat/Babble · GitHub
- Unique match positions by zmughal · Pull Request #6 · shadow-dot-cat/Babble · GitHub
- SubstituteAndReturn: contextual and chained substitute · Issue #7 · shadow-dot-cat/Babble · GitHub
- SubstituteAndReturn: chained and contextual by zmughal · Pull Request #8 · shadow-dot-cat/Babble · GitHub
- Package syntax: versions and blocks · Issue #9 · shadow-dot-cat/Babble · GitHub
- Add plugins for package block and package version by zmughal · Pull Request #10 · shadow-dot-cat/Babble · GitHub
- Update use of PerlTerm for PPR ≥ v0.001000 by zmughal · Pull Request #11 · shadow-dot-cat/Babble · GitHub
- PostfixDeref: Add support for postderef_qq, postfix ->$#* by zmughal · Pull Request #12 · shadow-dot-cat/Babble · GitHub
- PostfixDeref: translation using map construct does not work with push, etc · Issue #13 · shadow-dot-cat/Babble · GitHub
- DefinedOr: operator precedence for assignment + ConditionalExpression by zmughal · Pull Request #14 · shadow-dot-cat/Babble · GitHub
- PostfixDeref: direct dereference by zmughal · Pull Request #15 · shadow-dot-cat/Babble · GitHub
Perl::MinimumVersion
perl5
PPI
- Extending PPI · Issue #270 · Perl-Critic/PPI · GitHub
- The Keyword Question · Issue #273 · Perl-Critic/PPI · GitHub
PPR
- Bug #122794 for PPR: s///e RHS is not validated (rt.cpan.org #122794)
- Bug #143876 for PPR: Interpolation within quote-like with single-quote delimiters (rt.cpan.org #143876)
- Bug #143877 for PPR: More cases for postfix deref (rt.cpan.org #143877)
- Bug #143955 for PPR: Parsing of Perl*AccessNoSpace + postderef_qq (rt.cpan.org #143955)
- Bug #143966 for PPR: state declaration + attribute regression (rt.cpan.org #143966)