I have been recently working on and dogfooding a project that I call NNTP::Portal. It is meant to be a way to merge the "oldskool" world of newsreaders with content retrieved from other sources, mainly the World Wide Web.
Background
Usenet is network originally developed in the early 1980s that provides a distributed system for the delivery of messages, called articles, between servers that carry these messages (collectively called a news feed) in hierarchical groups based on topics, called newsgroups. Quite a few of the jargon and behaviours of Internet communication were originated or developed by users of this network. Users of Usenet are able to read and reply to articles on Usenet using software called newsreaders. You can see an example of both the messages and interfaces from the early days of Usenet here. It is also worth noting that most of the software that runs the Internet today was first announced via a Usenet posting.
Usenet's distributed nature allows for a mostly-free reign in terms of content, so there are inevitably problems that arise from having a flood of articles, many of which could be spam. Newsreaders have developed the means to address this need by adding features that can filter out unimportant messages; this is usually accomplished through the use of scoring or kill files. There are some other methods that have been developed, but they are not used as widely.
The Network News Transport Protocol is a standardised protocol developed in the mid-1980s to facilitate the communication of Usenet traffic both between peering servers and between a server and a client. It is described in RFC 977 and has been updated with extensions over the years.
Motivation
Today, in the year 2011, the major protocol used online is by far HTTP, which is the means of transportation for data on the World Wide Web. As you may be aware, this data is typically encoded in the HyperText Markup Language, or HTML, along with several other technologies which determine how a Web browser will display the data.
Today's Web sites are moving toward bringing more ways for users to participate in the generation and consumption of media by bringing the ability to interact with pages through the use of uploads, collaborative editing, ratings, recommendations, and comments. However, due to the client-server nature of HTTP, these interactions generally stay on one Web service and the only way to access this data is by going to that Web site. As a response to these incompatibilites between sites, Web feed1 formats and APIs have been used to get different Web services to talk to each other2. Many people have called these tools the pipes of the Web, in reference to Unix pipes, because they allow you to create a chain of transformations to get from one set of data to another.
This is great, but many of the efforts I have seen to that go through the work of moving data around are about either showing a cute visualisation or providing a way bringing that data to either the desktop or a mobile device. Each of these efforts have a different interface as well as different levels of interaction. Few have any extensibility to speak of and can only do a fixed action with the data. These are useful, but severely limiting when it comes to what can be done with a computer. A lack of a standard interface is not only confusing for users (it takes time to navigate and learn a new interface), but also negligent of accessibility needs. Missing extensibility means that any data not exposed via a feed/API will remain inside the browser or application.
Let us jump back for moment. Now, in the early days of computing, the fastest way to interact with a computer was through the keyboard. This is still true today for certain kinds of operations, specifically those involving text. As such, newsreaders were (and still are) largely keyboard-driven, allowing users to select and scan through large numbers of articles efficiently. Typically, these newsreaders had way of interacting with their environment, by having a built-in scripting language or pipes. This way, by extending the reach of newsreaders, one could build a toolkit that worked exactly how you wanted it to. For example, one could write script that, at a single keystroke, would grab a source code listing out of an article, compile it, and place it in the executable path. You could have such a script for every key on your keyboard. In the end, you are able to create an interface that matches the way you work.
This is what I want to bring to the Web. I'm not the only one.
Design
I decided to work with the NNTP protocol because
- It is standardised, therefore I do not need to write a specification nor a client.
- The standard is simple to implement.
Newsreaders have a history of working with large conversations and modern newsreaders have excellent threading support. There is also the very much needed ability to mark messages as read so that they are out of the way. Another action I find lacking on Web sites is the ability to postpone a message, i.e. to save a reply so that I can return to it later. I have lost many lengthy replies because I accidently switched to another page.
Newsreaders have these features and many more that facilitate two-way communication.
- It uses the Internet Message Format which has the advantage of being human-readable and, through MIME, extra data can be embedded in the message if necessary.
Tools
- Perl
- A scripting language that has an extensive library of modules (CPAN), as well as powerful text-processing tools (most notably, regular expressions).
- Moose
- An object framework for Perl that simplifies working with attributes, roles, and meta-objects.
- POE
- A framework for event-driven programming. It abstracts away much of the code that is common in network programming. I wish I had known about it when I was first learning the socket API.
- DBI
- A database abstraction library. It provides a consistent set of function calls whenever you need to connect, query, and retrieve data from a database.
- SQLite
- A small SQL database that requires no configuration. I chose SQLite as my first database backend for this very reason, but I may test other databases such as BerkeleyDB.
- Mail::Box
- A module for manipulating message headers and bodies.
Server layout
Right now, there is not much to the server. All it does it take NNTP commands
and periodically requests new messages from plugins. I am currently playing
with the idea of using roles to implement extra features for each database
backend, such as the OVERVIEW capability which sends a set of message headers
to the client in a tab-delimited format.
The current server layout is shown below

As you can see, it is rather simple, but it works. The only issue is that the updating is not realtime. One reason for this is that POE uses a single threaded model. So, future versions of the server will separate the server into separate threads that will use the message database concurrently.
The future server layout design so far is shown below

The purpose of the RPC server is to have a way for a user to query the state of plugins and retrieve specific information (e.g. notifications) that can not be done over the NNTP protocol alone (out-of-band).
The idea behind the job queue is that each plugin will be able to post jobs for plugin-specific workers to process. These jobs will most likely be scheduled so that they can poll for updates optimally (the specifics of which I have not worked out yet).
Two parts of the server design that I have not yet figured out are the message updating and the article posting mechanisms. By message updating, I mean when the message changes in the original source. Normal NNTP articles are meant to have immutable bodies, so I will need to see what is the best way to present these changes to the user as well as how the plugins will handle them. The other issue, article posting, has many parts to it, including whether the user has permission to post and how to indicate this without wasting the user's time.
Results
Well, I have to show what the program's output looks like, so here it is in the slrn newsreader:
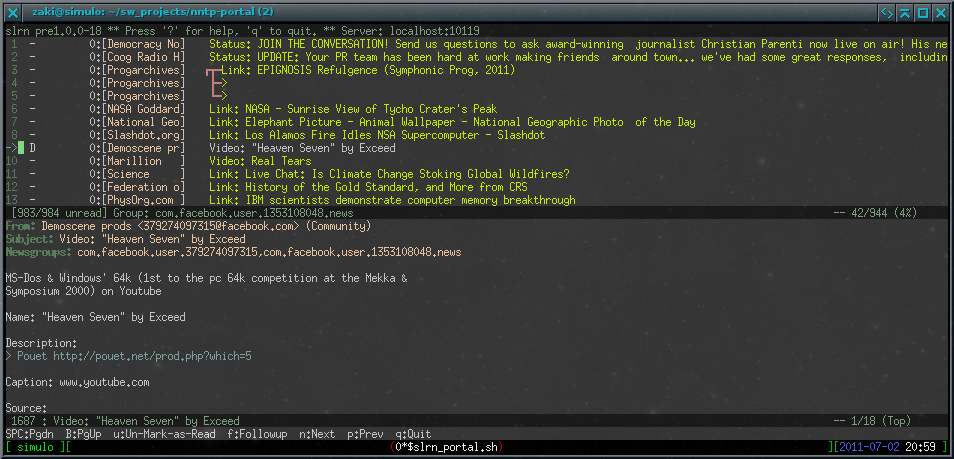
Currently, the database uses 1.6 KiB/message. I have also noticed that the Graph API can not retrieve messages from certain people. This is a permissions problem, so I will need to work on getting a way around it3. I would also like to tag people in posts on Facebook, but the API does not have a way of doing this, as far as I can tell.
Why‽
Well, I wanted to do some software engineering and I've recently discovered how much I like writing network software (this is the third server I've written in the past eight months and the first non-trivial one). Also, I've been really frustrated with the trends towards moving applications to the Web. One has to ask, how many of these applications can you really trust? How many let you see the source to the backend so that you can evaluate security? Few do4. In addition, one rarely gets to pull all the data from these services and sometimes the services have put in place terms of service that are hostile5 to third-party users. I want to see how far this project will take me.
I may even try to develop my own distributed service on top of NNTP. It will certainly be more lightweight and extensible than the current webservice offerings.
Related work
The following are browser-based tools that make extending web sites in the browser easy (if you know JavaScript):
And outside the browser:
Organizations:
Confusingly, these are also called newsfeeds. The similarity does not end there, as clients that pull Web feeds are also called news readers. Furthermore, it is entirely possible to use a NNTP newsreader to read Web feeds. ↩
There is also work on the Semantic Web and microformats, but these are not as widely used today. ↩
Thanks to @j3sus_h for pointing out the source of problem. ↩