When people go to my GitHub profile, the first thing they might notice is a contribution streak that is completely filled in with public contributions.
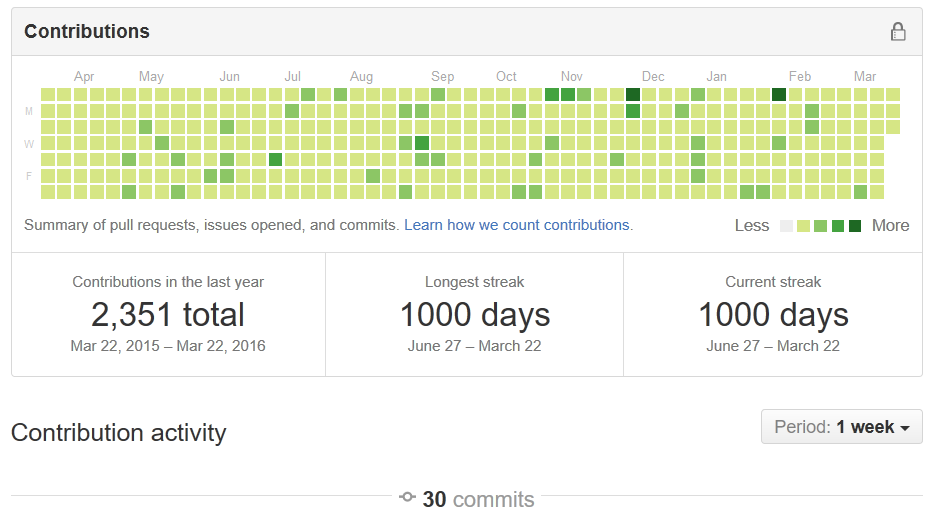 |
About three years ago, I decided that I would try to commit something every day. That felt like a ridiculous goal given that I was often only able to set aside one evening a week to working on side projects. I've always been too busy to focus on projects between all the time I spent on grad school, research, studying, commuting, and all my other responsibilities.
Why
So why would I do something like this? It would take up a decent chunk of time every day, so I needed some justification to keep me motivated.
I saw that I was writing plenty of code, but I was not finishing my projects. I would either take a break from a project because I was busy or jump to another more urgent project without leaving enough notes for completing the first project when my time freed up.
Working this way meant that the only projects that I could reliably finish were the kind that could be done in the course of a month.
I had many ideas that were more complex and time-consuming than these short projects, but at the same time, starting on larger projects was very daunting. There was a very real possibility that those larger projects would languish. I knew that I couldn't keep working like this.
This exercise was not meant to simply turn coding into a game. GitHub used to keep a count of the number of consecutive days of contributions (a "streak"), but I wasn't trying to use that as a kind of score. In fact, I didn't even know what that number represented until I started this whole endeavour!
How to solve it
Now you probably want to know how I did this. Like any habit that requires discipline, taking the plunge right away is not the best course of action. You want to gradually work your way up so that you can keep going past the first couple weeks. This is about endurance, not speed.
Ramping up
A good way to start is to practice your skills. I got plenty of this by working on the short projects that I mentioned before, but I wanted to take what I was doing further. My approach was to imagine that I was writing a program that other people would try to run even if that was not likely.
I would first apply this to school assignments. For example, I had an assignment that required me to implement k-means and k-means with RANSAC. I wrote my implementation of RANSAC so that I could pass in a function that would allow it to fit parameters to any model rather than just k-means. This way, if I returned to my source code months later, I would be able to quickly repurpose it. Other tips for writing better code include:
- Document the algorithms that you use in detail. Explain each step and cite the original papers that introduced the algorithm.
- Write tests. Even if your program is a small script, it can be tested. This will give you practice with techniques such as setting up a clean test environment and then tearing down the test environment.
- Use proper directory structure (e.g., for my assignments I used
src,gfx,paper,data, anddoc). - Create a build system (e.g., I would add a
Makefilethat zipped up the final submission of my report and code by runningmake dist). - Add instructions on how to run your project including a list of all the dependencies needed.
- Ensure that every commit that you make has a complete commit message that explains what you are doing. If you can write a paragraph, do so. It is difficult to understand why you made a change with just a single sentence fragment.
Sometimes it is easy to give up on writing better code because what you are working on is a research prototype or just a school assignment. I feel that is a poor excuse because practicing when programming-in-the-small prepares you for when you will be programming-in-the-large. You are freer to make mistakes and it is easier to learn when you have complete control over the direction of the project and you are not hindered by the technical debt of existing code.
I use this small project approach whenever I start learning anything new. You can use it to learn a new library, understand how to use a debugger effectively, or improve your version control skills.
Ideation
Now that you practiced on small programs, you need ideas to start working on larger programs. The way that has worked best for me is to read as much as possible. You can read books, articles, documentation, and even other code. Try to get ideas from other people especially if those ideas are far away from programming. Try to read about subjects that you have never really thought about such as horology or botany. With any luck, you'll come across concepts that will spark new ideas.
The reason why I recommend reading topics that don't have to do with programming is to help avoid a common pitfall that developers fall into: tool-building. Tool-building is creating a tool that can be used to solve other problems rather than solving the problem directly. While this is important and can be more fun than writing applications, it can easily become recursive and you may end up spending more time writing tools than actually thinking about your original problem. For example, instead of writing a build system for your project, you might start writing a package manager which in turn has its own problems to solve such as dependency resolution and service management. Trust me, you do not want to go down that road — it can lead to months of wasted effort.
To help avoid this, you need to reel in the ideas and focus on something that scratches an itch and solves a specific problem that you have (I call this annoyance-driven development). It may be surprising, but the most important step of problem-solving is defining the problem. If you define a problem well, it becomes easier to understand the steps that you need to take to solve it and the appropriate places to break down the problem into subproblems.
One thing that I am trying to do is make my designs and problem definitions more public so that others can use them and to possibly collaborate.
Leslie Lamport has written an article and given a few talks about the importance of writing blueprints and specifications before you write a line of code. Writing is a way of clarifying how you think and it makes finding the solution easier — so it is definitely worth taking the time to make a plan. Some of the trickiest problems that humanity faces are known as wicked problems and their difficulty stems from not being well-defined in terms of both requirements and the kinds of possible solutions to choose from. So don't make your problems more wicked than they have to be and take the time to design!
These plans do not have to be extremely detailed and it can actually be counterproductive to make them too intricate. Early on, I would try to research as much as possible about a problem, but then I would run out of time to implement the solution. A simple plan that can easily be changed when you have more information is enough to guide you.
Organisation
To help you define your problem, it is important that you organise your work. For large projects, it can be easy to get lost in a mass of data and ideas and you might get bogged down under all that weight before you even start the planning and implementation.
I use an outliner and personal wiki to handle all my projects. I put all my notes in there as well as a rough list of tasks that I need to complete for each project. This way I can keep track of many projects at once.
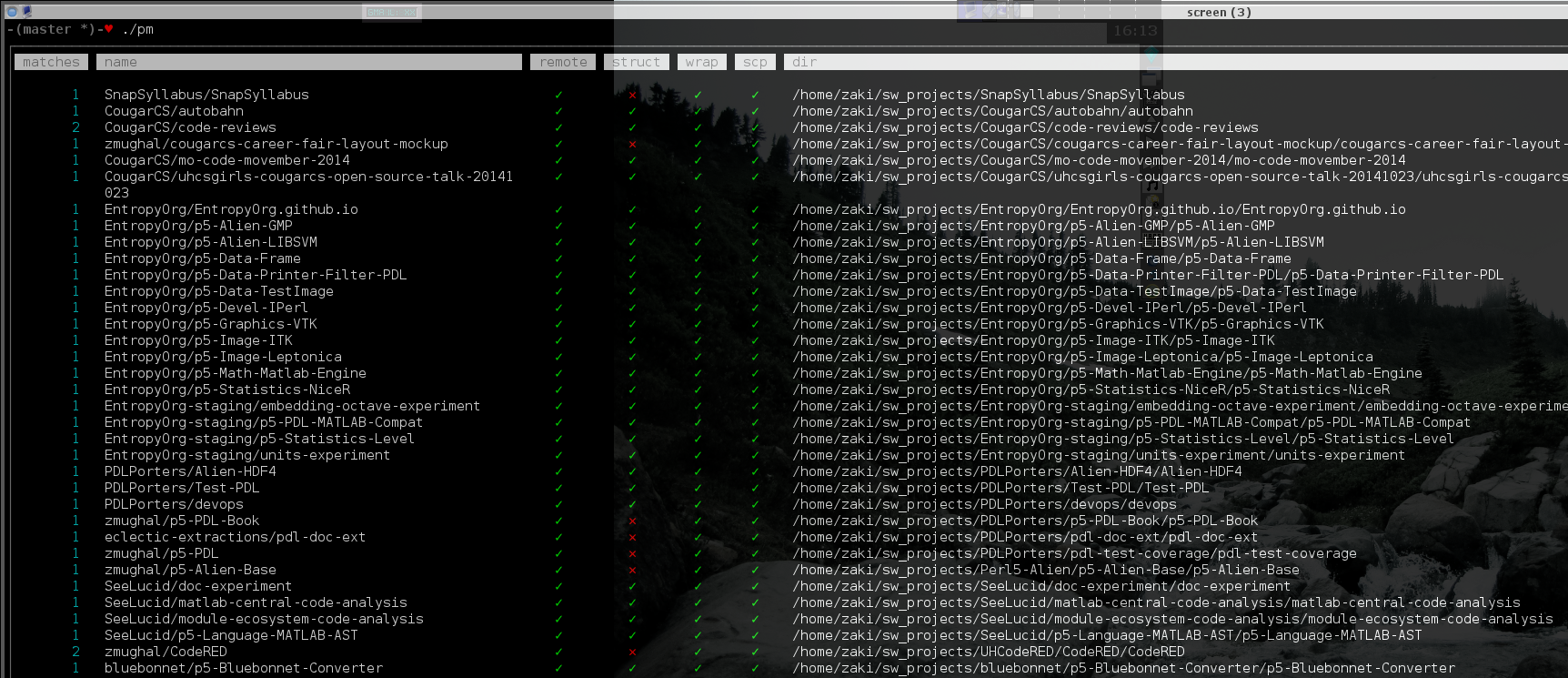
One of the issues that I hit after about two years into this daily routine was that I had too many projects going on at once which made it difficult to navigate to the exact set of files I needed. I had a real mess with 150+ directories all under one tree.
 |
I needed to come up with a project structure that could scale. I started by moving many of my projects from under my GitHub account into different GitHub organisations. This was a way of adding a namespace that grouped together projects that were related to each other. I then mirrored that structure on my computers as shown below:
project/
┣ organisation0/ [ organisation ]
┃ ┗ foo/ [ wrapper ]
┃ ┣ note/ [ notetaking ]
┃ ┗ foo/ [ repository ]
┗ organisation1/ [ organisation ]
┣ bar/ [ wrapper ]
┃ ┣ coverage/ [ code coverage ]
┃ ┣ reading/ [ reading material ]
┃ ┗ bar/ [ repository ]
┗ baz/ [ wrapper ]
┣ doc/ [ documentation ]
┗ baz/ [ repository ]
This places each repository's directory inside a directory with the same name which I call a "wrapper directory" which in turn is placed inside a directory with the name of the organisation that the repository is part of.
The purpose of this extra wrapper directory is to store auxiliary files such as notes, generated HTML documentation, and code coverage reports. I wrote a small script to make sure that all my projects used this structure because I was not going to do that 150 times!
 |
Without all this organisation, the overhead of figuring out what I need to work on today would exceed the free time I have available each day. If you are just starting, I recommend staying organised early on before it gets out of hand.
The human side of problem-solving
Those were some tips for the intellectual side of problem-solving, but we are not purely intellectual creatures. We need to address the human aspects of problem-solving.
Focus and Persistence
Any creative endeavour inevitably reaches roadblocks. You're going to be trying something new and then come to a problem that you just can't make headway on. Or you may just become so busy with the demands of life that you can't set aside time to think.
If you are going to try to work every day, how do you choose which of your projects to work on? Not every problem is created equally and it is not worth it to bang your head against the wall trying to solve a particularly thorny issue when you don't have enough time to figure it out.
You need to develop a way to evaluate your expectations for each problem so that you can triage between problems that can be solved immediately and problems that will need long-term thinking.
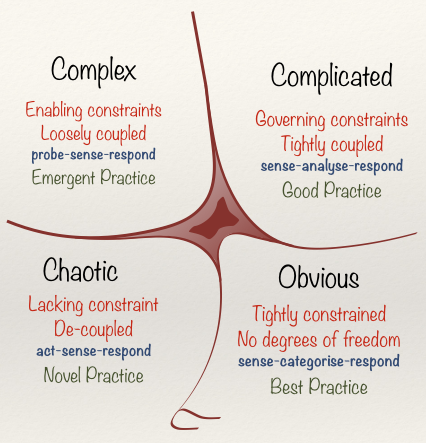
Dave Snowden has developed a terminology called the Cynefin framework for describing various kinds of problems. This framework is a good way for understanding what problem you are facing and what steps you should take to solve it.
 |
{kind=link}
In particular, I want to look at the complex and complicated domains because while these terms may appear synonymous, the Cynefin framework provides a clear distinction1:
| Class | Analysis | Solution | How to approach | Example |
|---|---|---|---|---|
| Complicated | You have a general idea of the questions that you need to ask (known unknowns). | Multiple correct solutions, but through expertise, we choose one that is appropriate (good practices). | Analyse the situation and make a plan. | Converting a program from a serial processing to parallel processing (profile the code and trace dataflow then replace the pessimal parts with better solutions). |
| Complex | You don't know what type of questions to ask (unknown unknowns). | Multiple possible solutions, but we need to experiment in order to obtain more knowledge about the problem (emergent solutions). | Experiment and evaluate to gather knowledge. | Processing unstructured data where you do not know the format ahead of time or possible sources of error (find the simplest thing that works and iterate). |
Once you have determined the kind of problem you are dealing with, you have an idea of how long it will take to solve it and what it means to make progress towards a solution. I use this to know if I should worry about picking a descriptive final name for my project or not. The convention I use is to name things differently by their purpose:
- Applications get a creative name which does not necessarily need to connect directly with what the application does (e.g., Curie for my document reader project's GUI).
- Libraries get a name based on what language they are written for and if the library is targeting a language with namespaces, the descriptive namespace that it will take (e.g., p5-Statistics-NiceR for a Perl 5 library that interfaces to the R programming language for doing statistical analysis).
- For experimental ideas that are not fully-fledged, I add the suffix "-experiment" (e.g., pdf-extraction-experiment where I explore methods for applying semantic labels to different regions of PDFs for scientific articles).
The problems found in applications and libraries usually fall into either the Obvious or Complicated domains while the experimental problems are usually in the Complex domain. By using a consistent naming scheme, I can scan through my list of projects and choose which one to work on based on how much time I can allocate, that is, either a short period for Obvious problems, a medium-sized period for Complicated problems, and much longer periods for Complex problems.
Assigning such expectations ahead of time also lets me know when to drop a problem. For example, if I spend 6 hours of work in a week on something that should be Obvious, I realise that it is trickier than I thought. I then take whatever I learned in my attempt and ask others for help. I then leave that problem alone until I can come back with fresh ideas.
This approach is how I try to avoid burnout. Trying to work on a problem and not getting any results is exhausting. That's one of the problems with software development: you have to do a lot of work before you can get feedback. There is a temptation to rewrite your project from scratch when the difficult bugs pile up, but if you do that, you'll never solve the problem!
The guilt sets in
 |
If you have all these projects, you might feel like you don't have time for non-productive entertainment. For a while, I also felt this way. But we all have our limits and need time to relax. At the end of a very busy day, I often felt too drained to even pick a project to focus on. I would dabble in some code and make an inconsequential change.
After facing this problem on multiple occasions, I decided to turn the problem on its head. What if instead of trying to do work at the end of the day, I worked on my projects earlier? But when?
I decided that I would get up early and work from around 3 to 6 in the morning. This did mean that I would have to go to bed earlier, but working in these early hours was quite beneficial.
I could work without any interruptions because most people would be asleep. Try to keep track of how many times a day you are interrupted when you are in the middle of something and how much time you lose that way. You'll be surprised!
The sense of accomplishment I would get out of solving something before I even left my house would give me energy for the rest of the day. This was great for me as I am more of a night owl and it takes me a while to slough off the grogginess of sleep inertia. If I got up earlier to work, I was ready for my commute.
Finally, I could apply this routine even when I was on vacation. If I got everything done before I set out for the day, I could enjoy my time and not think about getting home before the stroke of midnight.
Improvement
One of the goals I set for myself is to always improve how I do things. If I just use the same techniques over and over again without improving them, I'm not learning anything. There is no short path to becoming a better software engineer — it takes years of learning and if you stop learning, you will stay in the same place and work on the same problems over and over.
When I started, I didn't even take the time to write tests! They took too long to write and it wasn't code. But I was mistaken. Writing tests is just as important as any other code. While your application and library code is telling the computer how to perform actions, your comments and test code are telling people what your intentions were.
This becomes even more important when you are starting to distribute your code for others to use. Just because it works on your computer, doesn't mean it will work on others. I now keep around VMs just so that I can test what I'm writing on Windows, BSDs, and Solaris.
Writing is also a way to get more commits. I publish some project wikis and my Vim spelling dictionary file on GitHub which means even if I am not strictly writing code, it shows up as a contribution. Writing is as important as code!
Communicating your intentions is even more important when you start working with other people. It may be as simple as telling people that "I am working on this bug" and giving updates on your progress. As your projects and teams get larger, communication becomes the overriding principle that drives success.
One way to practice this is to make your writing public. When you write private notes, you might not put as much effort into it just as you might with code that nobody else has to see. I did this by publishing my notes online and presenting at local user groups and putting those slides online. Put yourself out there.
Making mistakes
One of the fears that people have with making their work public is that they aren't publishing something that is perfect2. But if you are also always learning, you will always be raising the bar for your personal best. It's better to accept that everything is a work in progress. Having version control also gives you more leeway to make mistakes. Just work on a branch and use it to try different solutions without worrying that it isn't quite done.
If you're trying to do new things, you might hit upon another fear: imposter syndrome. This can be a very damaging to your personal development because it can stop you from taking risks and working on unfamiliar problems. It is important to remember that every person starts from the bottom. Dijkstra wrote that
The competent programmer is fully aware of the strictly limited size of his own skull; therefore he approaches the programming task in full humility, and among other things he avoids clever tricks like the plague.
This humility is a very useful approach to life in general. When you no longer feel insecure by a lack of knowledge, you can open your mind to exploring more ideas as a complete beginner. That's just the first step to becoming an expert.
Final thoughts
I had no doubt that I could pull off something like this if I tried, but was it worth making it a priority? I believe that it was. There were many times that I would work on a side project and what I learned from that side project would transfer to my work. For example, I learned how to test scientific code by working on the test suite for PDL and I learned about platform-specific toolchains by working on Alien-Base. These skills were very important for when I wrote my thesis and by working on them in isolation from all my other problems, I was able to debug faster.
You can read more about Cynefin in the Harvard Business Review and at Everyday Kanban ↩
This is a common argument for not publishing academic software. Matt Might argues against this and provides a license for academics that absolves authors from the shame of their hacks. ↩